


「あのガイドラインの第何条に、例外規定があったはず…」
弁護士の業務では、官公庁が発行するガイドライン、通達、逐条解説、事務所内マニュアルなど、膨大な参照資料を日常的に扱います。法律の条文は頭に入っていても、行政解釈の細部やガイドラインの具体的な記述を正確に記憶するのは困難です。
必要な箇所を探すために、数十〜数百ページの資料を何度もスクロールする。キーワード検索をかけても、知りたいことと文書中の表現が一致しない。こうした「探す時間」は、弁護士の貴重な知的作業を圧迫しています。
AILEXのナレッジベースAIは、この問題に正面から応えます。PDFやWord文書をアップロードするだけで、その資料の範囲内でAIが質問に答える専用チャットが完成します。Google NotebookLMのような体験を、弁護士の守秘義務に配慮した環境で提供する機能です。
この機能でできること
ナレッジベースAIは、3つのステップで動作します。
ステップ1 — 資料を読み込ませる。 PDF・TXT・Markdown・Word文書を最大10件までアップロードできます。AILEXがテキストを自動抽出し、検索可能な形に変換します。
ステップ2 — AIが資料を理解する。 抽出されたテキストは約1,600文字ずつのチャンク(断片)に分割され、OpenAIの最新Embeddingモデルでベクトル化(数値化)されます。これにより、キーワードの完全一致ではなく「意味的に近い」内容を検索できるようになります。
ステップ3 — 質問すると、引用付きで回答する。 チャット画面で質問を入力すると、AIが資料内の関連箇所を自動で特定し、その内容に基づいて回答します。回答には「出典: ○○ガイドライン p.42」のように参照元が明示されるため、根拠の確認が容易です。
重要なのは、AIが資料の範囲外の情報で回答を「でっちあげる」ことがない点です。読み込ませた資料に記載がない質問には、「この資料には記載がありません」と明示的に返答します。ハルシネーション(AI幻覚)のリスクを構造的に抑制する設計です。
利用シーンと具体例
シーン1: 個人情報保護委員会ガイドラインの確認
個人情報の取り扱いに関する相談を受けた弁護士が、ガイドライン(通則編・外国提供編・仮名加工情報編)のPDF3件をナレッジベースに登録。
「要配慮個人情報の取得に本人同意が不要な例外ケースは?」と質問すると、通則編の該当ページから5つの例外類型を引用付きで回答します。さらに「外国の第三者提供で同意が不要になるのはどのような場合か?」と続ければ、外国提供編の該当箇所に基づいて回答が返ります。
資料をまたいだ横断的な質問にも対応できるため、複数のガイドラインを一つのナレッジベースにまとめておくと効率的です。
シーン2: 事務所内マニュアルの共有
事務所内の業務マニュアル(新人向け手順書、経理処理規程、書類作成基準など)をナレッジベースに登録しておくことで、スタッフからの「このケースはどう処理するのか」といった質問に、マニュアルに基づいた正確な回答をAIが返せるようになります。
ベテランの先輩に聞きづらい細かな手順も、ナレッジベースに質問すれば即座に回答が得られます。
シーン3: 特定分野の通達・解釈集の活用
労働基準法関連の通達集や、消費者契約法の逐条解説など、特定分野の参照資料をナレッジベースに登録。案件の法的検討を進める際に、「36協定の特別条項で上限を超えられる要件は?」「消費者契約法10条の前段要件と後段要件の関係は?」といった実務的な質問に、通達・解釈の原文に基づいた回答を得られます。
条文の記憶に頼らず、常に原典に立ち返りながら検討を進められるのが、ナレッジベースAIの最大の利点です。
使い方ガイド
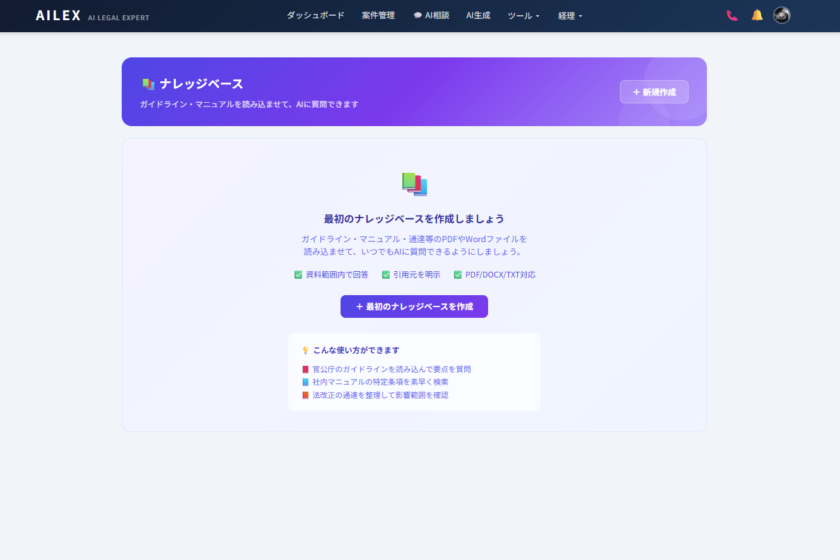
ナレッジベースの作成
- サイドバーの「📚 ナレッジベース」をクリック
- 「+ 新規作成」ボタンを押す
- 名前(例: 「個人情報保護委員会ガイドライン」)と説明(任意)を入力
- 「作成」をクリックすると、文書管理画面に遷移します
名前は後から変更できます。用途がわかりやすい名前をつけることを推奨します。
文書のアップロード
文書管理タブで「アップロード」ボタンからファイルを選択します。
対応形式はPDF、TXT(テキスト)、MD(Markdown)、DOCX(Word)の4種類です。1つのナレッジベースにつき最大10件まで登録できます。
アップロード後、AILEXは以下の処理を自動で実行します。
- テキスト抽出 — PDFからテキストを読み取り(またはWord/テキストファイルの内容を取得し)
- チャンク分割 — 約1,600文字(800トークン)ごとに、100トークンのオーバーラップを持たせて分割
- ベクトル化 — 各チャンクをOpenAI text-embedding-3-smallモデルで1,536次元のベクトルに変換
処理が完了すると、ステータスが「✅ 準備完了」に変わり、AIへの質問が可能になります。
10ページ程度のPDFであれば、処理時間は数秒〜十数秒です。100ページを超える大きな文書でも、通常1〜2分以内に完了します。
注意: スキャン画像のみのPDF(テキストデータを含まないPDF)はテキスト抽出ができません。OCR処理済みのPDF、またはテキストを含むPDFをご使用ください。
AIに質問する
「AIに質問」タブを開き、チャット入力欄に質問を入力してEnterキーを押します(またはShift+Enterで改行)。
質問のコツは以下の通りです。
- 具体的に聞く — 「この資料の内容を教えて」より「第5条の例外規定を教えて」の方が的確な回答を得られます
- 一度に一つの論点 — 複数の論点を含む質問は分けた方が、引用元の特定が正確になります
- 資料にある表現を使う — ガイドライン中の用語をそのまま使うと、類似チャンクの検索精度が向上します
回答には参照元(文書名・推定ページ番号・類似度スコア)が表示されます。「📄 参照元」を展開すると、AIが回答に使用したチャンクの一覧を確認できます。
サジェストボタン
初回アクセス時は、3つのサジェストボタンが表示されます。
- 📋 資料の概要 — 「この資料の概要を教えてください」
- 🔑 重要ポイント — 「重要なポイントを3つ挙げてください」
- ⚠️ 例外規定 — 「例外規定について教えてください」
まず「資料の概要」から始めて、AIが文書を正しく読み取れているか確認することを推奨します。
文書の追加・削除
ナレッジベースの文書管理タブから、いつでも文書の追加や削除が可能です。文書を削除すると、その文書から生成されたチャンクもすべて削除されます。新しい版のガイドラインが公開された場合は、旧版を削除して新版をアップロードするだけで更新が完了します。
チャット履歴
質問と回答の履歴はナレッジベースごとに保存されます。過去のやり取りを参照できるほか、「🗑 履歴クリア」で全履歴を削除することも可能です。
技術仕様
ベクトル検索の仕組み
ナレッジベースAIの中核は、RAG(Retrieval-Augmented Generation)と呼ばれる技術です。
通常のAIチャットでは、AIモデルの学習データのみに基づいて回答が生成されるため、学習していない文書の内容について正確に答えることができません。RAGは「まず関連する資料を検索し、その内容をAIに渡して回答を生成させる」という二段階のアプローチで、この問題を解決します。
具体的な処理の流れは以下の通りです。
- ユーザーの質問文をベクトル化(数値の配列に変換)
- ナレッジベース内の全チャンクのベクトルと、コサイン類似度を計算
- 類似度が高い上位5チャンクを取得
- 質問文と5つのチャンクをClaude APIに送信
- Claudeが「参照資料の範囲内で」回答を生成
類似度が0.3未満のチャンクは「無関連」として除外されるため、的外れな情報がAIに渡されるリスクを低減しています。
XServer環境での実装
一般的なRAGシステムではPineconeやMilvusなどの専用ベクトルデータベースを使用しますが、AILEXはXServer共有ホスティング環境で動作するため、これらは利用できません。
AILEXでは、MySQLのBLOBカラムにベクトルをバイナリ保存し、PHP内でコサイン類似度を計算する方式を採用しています。1つのナレッジベースあたり最大1,000チャンク×1,536次元×4バイト=約6MBのメモリ使用量であり、PHPのメモリ制限内で十分に処理可能です。検索応答時間は推定100ms以内です。
対応ファイル形式
| 形式 | 拡張子 | テキスト抽出方法 |
|---|---|---|
| PdfTextExtractor(AILEX独自のPHP PDF解析エンジン) | ||
| テキスト | .txt | ファイル直接読み取り |
| Markdown | .md | ファイル直接読み取り |
| Word | .docx | ZipArchiveでXMLを展開してテキスト抽出 |
制限値
| 項目 | 上限 |
|---|---|
| 1ナレッジベースあたりの文書数 | 10件 |
| 1ナレッジベースあたりのチャンク数 | 1,000チャンク |
| チャンクサイズ | 約1,600文字(800トークン) |
| チャンクオーバーラップ | 約200文字(100トークン) |
| 回答時の参照チャンク数 | 上位5件 |
| チャット履歴の保持件数 | 直近100件 |
PII自動マスキング — 守秘義務との両立
ナレッジベースAIでは、PII(個人識別情報)保護について以下の設計を採用しています。
ユーザーの質問テキスト — PIIMaskerを適用してからClaude APIに送信します。質問中に含まれる氏名・住所・電話番号等は自動的にプレースホルダに置換され、回答生成後に復元されます。
文書テキスト(チャンク) — ナレッジベースに登録する文書は、ガイドライン・通達・マニュアルなどの参考資料を想定しており、通常は個人情報を含みません。このため、チャンクテキスト自体にはPIIMaskerを適用していません。
重要な制約として、依頼者の個人情報を含む文書(陳述書、相談記録等)をナレッジベースに登録することは推奨しません。 そのような文書は、AILEXの既存機能(AIチャット、文書分析等)でPIIMaskerが適用される環境で扱ってください。
ナレッジベースAIは「弁護士自身の調査・学習を支援するツール」として設計されており、弁護士法72条が規定する「法律事務の取扱い」には該当しません。
処理コスト
ナレッジベースAIの利用コストは、AI SaaSの中でも非常に低廉です。
初回登録コスト(文書アップロード時)
| 処理 | API | 単価 | 10ページPDFの場合 |
|---|---|---|---|
| テキスト抽出 | ローカル処理 | 無料 | ¥0 |
| チャンク分割 | ローカル処理 | 無料 | ¥0 |
| ベクトル化 | OpenAI Embeddings | $0.00002/1Kトークン | 約¥0.3 |
10ページのPDFを登録するコストは約0.3円です。100ページの文書でも約3円にすぎません。
質問コスト(1回の質問あたり)
| 処理 | API | 単価 | 1質問あたり |
|---|---|---|---|
| 質問ベクトル化 | OpenAI Embeddings | $0.00002/1Kトークン | 約¥0.01 |
| コサイン類似度計算 | ローカル処理 | 無料 | ¥0 |
| 回答生成 | Anthropic Claude | 約$0.02/回 | 約¥3 |
| 合計 | 約¥3/質問 |
1日10回質問しても月額約900円。弁護士が資料を手動で検索する時間(1回あたり5〜15分)を考えれば、コストパフォーマンスは極めて高いといえます。
AIエージェントとの連携
AILEXのAIエージェント(画面右下の🤖ボタン)からも、ナレッジベースの検索が可能です。
エージェントに「個人情報保護のガイドラインで、要配慮個人情報について教えて」と質問すると、search_knowledge_baseツールが自動的に呼び出され、該当するナレッジベースから関連情報を取得して回答を構成します。
ナレッジベースを直接開かなくても、エージェントを通じて自然言語で横断的に検索できるため、「あの資料に書いてあったはず」という曖昧な記憶でも情報にたどり着けます。
既存機能との違い
AILEXには複数のAI機能がありますが、ナレッジベースAIは以下の点で他の機能と異なります。
AIチャット(💬 AI相談)との違い — AIチャットはClaudeの汎用知識に基づいて回答するのに対し、ナレッジベースAIは「読み込ませた資料の範囲内のみ」で回答します。資料に記載がなければ「記載がありません」と答えるため、ハルシネーションのリスクが構造的に低くなっています。
全文テキスト検索との違い — 全文検索はキーワードの完全一致(またはFULLTEXTインデックスによる部分一致)で文書を探しますが、ナレッジベースAIはベクトル類似度検索により「意味的に近い」内容を見つけます。「例外規定」と「適用除外」のように、表現が異なる同じ概念にもヒットします。
ファクトチェックとの違い — ファクトチェック(Perplexity API)はインターネット上の情報源で内容を検証しますが、ナレッジベースAIはユーザーが指定した資料のみを情報源とします。非公開のガイドラインや事務所内マニュアルなど、インターネット上にない資料に対してはナレッジベースAIが唯一の選択肢です。
今後の拡張予定
ナレッジベースAIは今後、以下の機能拡張を予定しています。
- AIチャットからの参照 — AIチャット(/chat)画面に「📚 ナレッジベースを参照」ボタンを追加し、通常のチャット中にナレッジベースのコンテキストを注入できるようにします
- AI文書生成との連携 — テンプレートからの文書生成時に、ナレッジベースの内容を参照して生成精度を向上させるオプションを追加します
- ファクトチェック連携 — ナレッジベースの回答に対して、Perplexity APIによるファクトチェックをワンクリックで実行できるようにします
- 事件文書からの追加 — 事件の文書管理画面に「📚 KBに追加」ボタンを配置し、事件に関連する参考資料をナレッジベースに直接追加できるようにします
よくある質問(FAQ)
Q. どのような文書を登録すべきですか?
官公庁が発行するガイドライン、通達、逐条解説、業界団体の基準書、事務所内の業務マニュアルなど、繰り返し参照する参考資料が適しています。依頼者の個人情報を含む文書(陳述書、相談記録等)の登録は推奨しません。
Q. スキャンしたPDFは使えますか?
テキストデータを含むPDF(テキスト選択が可能なPDF)は使用できます。画像のみのスキャンPDF(テキスト選択ができないPDF)はテキスト抽出ができないため、あらかじめOCR処理を行ったPDFをご使用ください。
Q. 1つのナレッジベースに何ページまで登録できますか?
明確なページ数上限はありませんが、チャンク数の上限は1,000です。1ページあたり約1〜2チャンクが生成されるため、目安として500〜1,000ページ程度まで対応できます。それ以上の場合は、分野別に複数のナレッジベースに分割することを推奨します。
Q. ナレッジベースの内容は他のユーザーに見えますか?
いいえ。ナレッジベースはユーザーごとに完全に分離されています。自分が作成したナレッジベースのみが表示・利用可能です。
Q. 回答の精度はどの程度ですか?
資料に明確に記載されている内容については高い精度で回答しますが、あくまでAIによる参考情報です。重要な法的判断については、必ず原文を直接確認してください。回答に表示される「📄 参照元」から、AIが根拠としたチャンクの内容を確認できます。
Q. 質問ごとにAPI料金がかかりますか?
はい。1回の質問あたり約3円のAPI料金が発生します。ただし、AILEXのProプラン内で提供される機能であり、質問回数による追加課金はありません。
Q. チャット履歴はどこに保存されますか?
AILEXのサーバー上のデータベースに暗号化通信で保存されます。外部サービスには送信されません(質問テキストのPIIマスキング後のClaude API送信を除く)。チャット履歴はいつでも削除可能です。
免責事項
ナレッジベースAIは、弁護士の調査・学習を支援する補助ツールです。AIが生成する回答は参考情報であり、法的助言を構成するものではありません。回答内容の正確性については、必ず弁護士ご自身が原文を確認のうえ、最終的な判断を行ってください。
ナレッジベースに登録した文書のテキストは、チャンク単位で外部AI API(Anthropic Claude)に送信されます。依頼者の個人情報を含む文書の登録は推奨しません。質問テキストについてはPII自動マスキングが適用されますが、文書テキストには適用されませんのでご注意ください。
AILEX — 検証可能なAIリーガルOS
ガイドラインを読み込ませて、いつでもAIに質問。探す時間を、考える時間に。
🔗 https://ailex.co.jp 📧 info@ailex.co.jp LINE: https://lin.ee/P9JAWZp